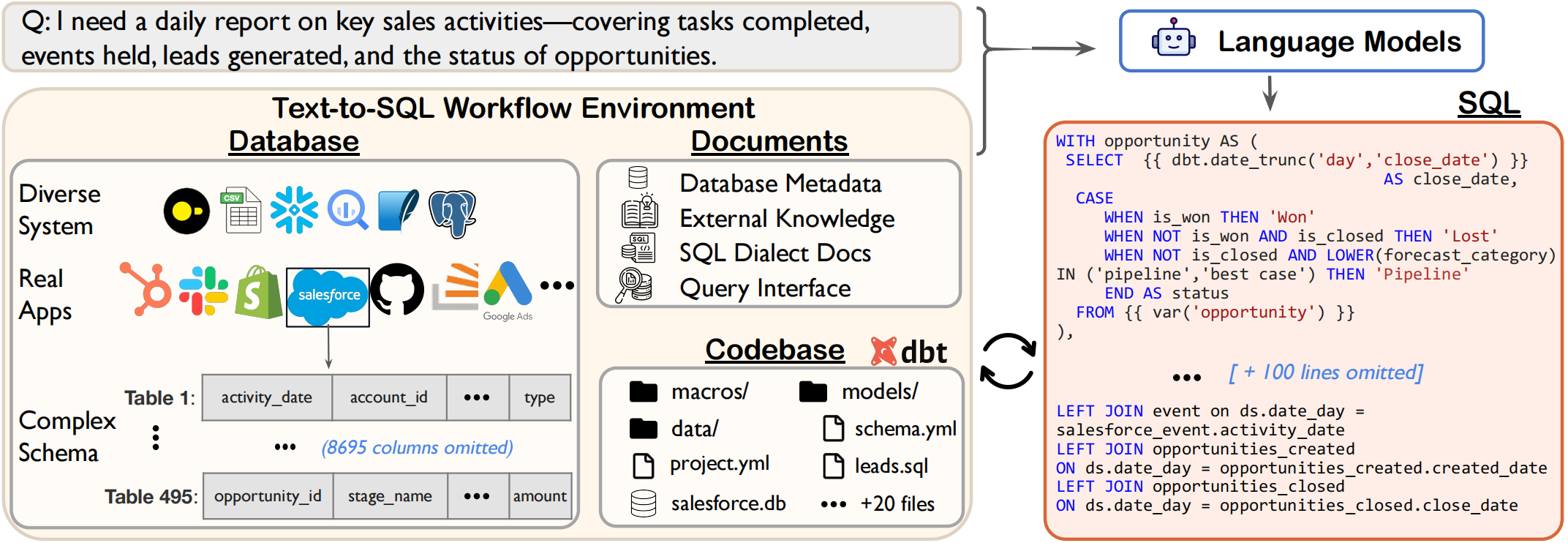
About Spider 2.0
Spider 2.0 is an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges.
News
-
2024-10-29:
Major update!
- We fixed the evaluation-suite issue, so scores are now more accurate and stable, and have refreshed the affected methods on the leaderboard.
- If you can cover the Snowflake hosting cost (spider2-snow remains free by default, but queries are queued), we can share the Spider2 Snowflake data directly with your Snowflake project. See Spider2_Data_Host.md for details.
- If you hit MF2A connection errors (meaning your credentials cannot access the Snowflake warehouse), check Credential_issue.md for guidance and review issue #143 for context.
- 2025-05-22: We have created a new task setting, Spider2-DBT, and removed the original Spider2 setting. Spider2-dbt consists of only 68 tasks, enabling quick and smooth benchmarking with spider-agent-dbt . It is a comprehensive, repository-level text-to-SQL task.
- 2025-04-20: We provide the ground-truth tables for spider2-lite and spider2-snow to help quick benchmarking and analysis. However, when using this setting, you must indicate that you are using oracle tables.
- 2025-01-10: Please refer to the data update log to track changes in the evaluation examples. The leaderboard results will also change dynamically accordingly.
- 2025-01-07: Please note that we do not recommend using the Spider 2.0 Gold SQL we released for SFT, as it may affect the fairness of evaluation and hinder better benchmarking of the model's SQL capabilities. The release of Gold SQL is intended to help users design prompts.
- 2024-12-26: Using Spider-Agent to benchmark your LLMs! Considering the widespread attention to the traditional text-to-SQL setting, we now recommend using spider-agent-lite and spider-agent-snow to work with spider2-lite and spider2-snow for benchmarking your LLMs. The final output should be CSV files, not SQLs.
- 2024-12-24: Considering the many evaluation requirements, we have decided to release all examples and gold answers for self-evaluation. However, only a small amount of gold SQL is available. The leaderboard is still active. To have your method officially validated and upload your scores to the leaderboard, please follow the submission guidance.
Why Spider 2.0?
Now, in the era of Large Language Models (LLMs), we present Spider 2.0 to advance code generation, particularly text-to-SQL capabilities.
This new benchmark offers a more realistic and challenging test of LLMs' performance on complex enterprise-level text-to-SQL workflows, involving complex data environments (e.g., >3000 columns), multiple SQL dialects (e.g., BigQuery, Snowflake), and diverse operations (e.g., transformation, analytics).
Notably, even the advanced LLMs-o1-preview solve only 17.1% of Spider 2.0 tasks. For widely-used models like GPT-4o, the success rate is only 10.1% on Spider 2.0 tasks, compared to 86.6% on Spider 1.0, underscoring the substantial challenges posed by Spider 2.0.
| Setting | Task Type | #Examples | Databases | Cost |
|---|---|---|---|---|
| Spider 2.0-Snow | Text-to-SQL task | 547 | Snowflake(547) | NO COST!😊 |
| Spider 2.0-DBT | Code agent task | 68 | DuckDB (DBT)(68) | NO COST!😊 |
| Spider 2.0-Lite | Text-to-SQL task | 547 | BigQuery(214), Snowflake(198), SQLite(135) | Some cost incurred |
Acknowledgement
We thank Snowflake for their generous support in hosting the Spider 2.0 Challenge. We also thank Minghang Deng, Tianbao Xie, Yiheng Xu, Fan Zhou, Yuting Lan, Per Jacobsson, Yiming Huang, Canwen Xu, Zhewei Yao, and Binyuan Hui for their helpful feedback on this work. The website and submission guidelines are greatly inspired by BIRD-SQL, and we thank them for their contributions.

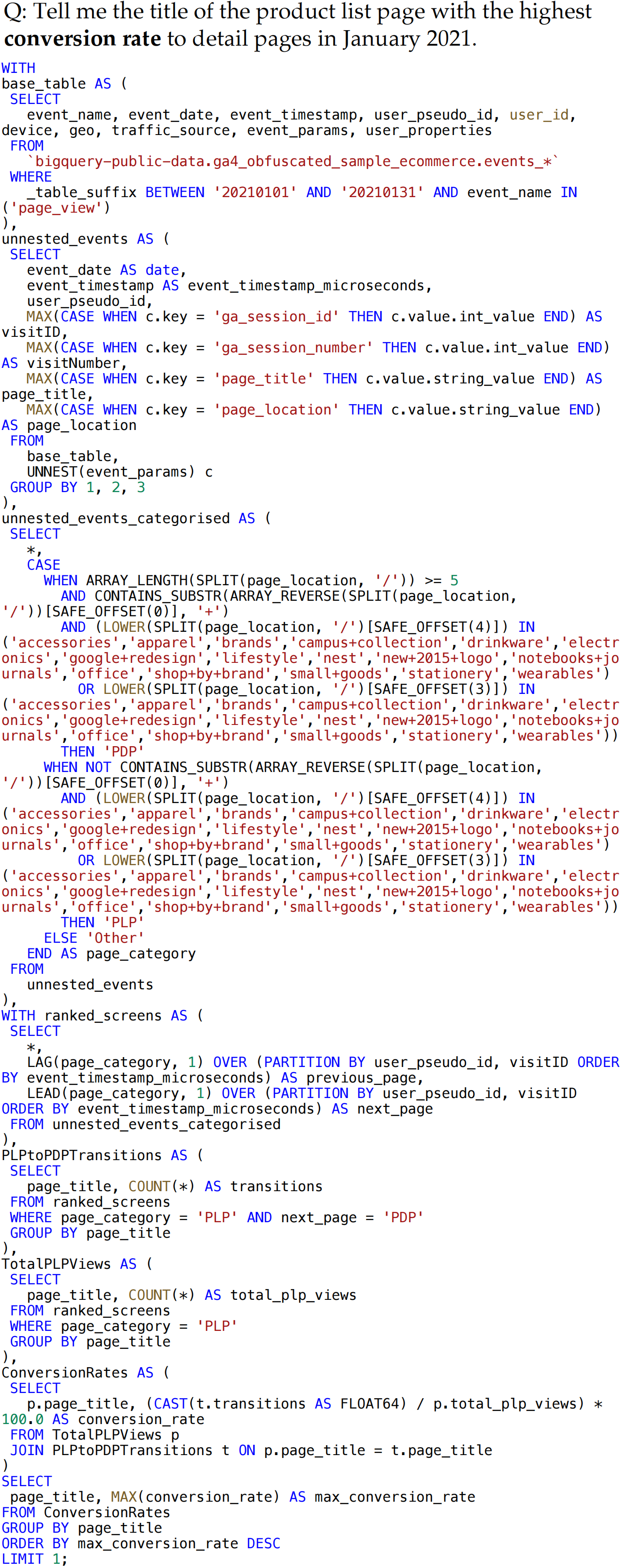
Data Examples
Have Questions?
Citation
@article{lei2024spider,
title={Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows},
author={Lei, Fangyu and Chen, Jixuan and Ye, Yuxiao and Cao, Ruisheng and Shin, Dongchan and Su, Hongjin and Suo, Zhaoqing and Gao, Hongcheng and Hu, Wenjing and Yin, Pengcheng and others},
journal={arXiv preprint arXiv:2411.07763},
year={2024}
}
Spider 2.0-Snow is a self-contained text-to-SQL task that includes well-prepared database
metadata and documentation, includes 547 examples, all hosted on
Snowflake, which offers participants free quotas.
Methods with -* use special settings (ground-truth tables) and are not included in the ranking.
Since we continually check the accuracy of the evaluation metrics (while the questions remain fixed), the scores may change slightly over time.
| Rank | Method | Score |
|---|---|---|
|
Native mini usenative.ai |
90.31 | |
|
Ask Data with Relational Knowledge Graph AT&T CDO & RelationalAI |
86.28 | |
|
ByteBrain-Agent ByteDance Infra System Lab |
84.10 | |
|
AiCheng Agent alibaba_cfo_tech |
82.81 | |
|
Prism Swarm + Claude-Sonnet-4.5 Paytm |
82.63 | |
|
LingXi Agent + Claude-Sonnet-4.5 Ant Group |
79.89 | |
|
Arctic-FLEX Snowflake AI Research |
75.14 | |
|
Sophon-Agent ByteDance DataPlatform LLM |
74.04 | |
|
QiSi-SQL + Deepseek3.2 Ant Group Tech Risk |
70.38 | |
|
PExA Bloomberg - AI Engineering group |
70.20 | |
|
Chicory AI Agent + Claude Sonnet 4.5 + Opus 4.5 Judge Chicory AI |
67.28 | |
|
SSDAT + GPT-5 |
65.63 | |
|
DSR-SQL + DeepSeek-R1 GDUT DMIR Lab [Hao et al. '25] |
63.80 | |
|
ReFoRCE + o3 Hao AI Lab x Snowflake [Deng et al. '25] |
62.89 | |
|
WindAgent + Claude-4-Sonnet MeiTuan AI For FinData |
61.43 | |
|
PAI-DataSurfer Agent Alibaba Cloud Computing Platform |
60.33 | |
|
AutoLink + DeepSeek-R1 HUST VLR Lab [Wang et al. '25] |
54.84 | |
|
Meituan-agent Meituan FinData Intelligence |
45.34 | |
|
AgenticView + GPT-5-mini Griffith BigData Lab, Griffith University |
40.95 | |
|
Chat2DB-Agent + Claude-4-Sonnet Chat2DB |
38.39 | |
|
ReFoRCE + DeepSeek-V3 |
38.03 | |
|
ReFoRCE + o1-preview Hao AI Lab x Snowflake [Deng et al. '25] |
31.26 | |
| Spider-Agent + Qwen3-Coder | 31.08 | |
| Spider-Agent + Claude-4-Sonnet-20250514 | 25.78 | |
| Spider-Agent + Claude-3.7-Sonnet-20250219 | 24.50 | |
| Spider-Agent + Claude-3.7-Sonnet-20250219-Thinking | 24.31 | |
| Spider-Agent + o1-preview | 23.58 | |
| Spider-Agent + o1-2024-12-17 | 23.21 | |
| Spider-Agent + o3-mini-2025-01-31 | 19.20 | |
|
Spider-Agent + Claude-3.5-Sonnet-20241022 AWS ProServe |
19.01 | |
| Spider-Agent + Claude-3.5-Sonnet-20241022 | 15.54 | |
| Spider-Agent + Gemini-2.0-Pro | 13.89 | |
| Spider-Agent + GPT-4o-2024-11-20 | 12.98 | |
| Spider-Agent + DeepSeek-R1 | 10.55 | |
|
CollideNL2SQL + GPT-4o Collide Tech |
9.68 | |
| Spider-Agent + QwQ-32B | 8.96 | |
| Spider-Agent + DeepSeek-V3 | 8.78 | |
| Spider-Agent + Qwen2.5-Coder-32B-Instruct | 5.48 | |
| Dail-SQL + GPT-4o | 2.20 | |
| CHESS + GPT-4o | 1.28 | |
| DIN-SQL + GPT-4o | 0.00 | |
| SFT CodeS-15B | 0.00 |